

想在 VPS 上跑 AI 应用,但不知道买什么配置?这篇文章按轻量、中等、重度三个级别,把主流 AI 应用的实际配置需求列清楚,每个级别给出具体的 VPS 推荐和一键部署命令。不讲理论,直接告诉你:跑什么应用、买什么机器、怎么一键装好。
先看总览:
| 级别 | 典型应用 | 最低内存 | 推荐 VPS | 最低年付 |
|---|---|---|---|---|
| 轻量 | n8n、LobeChat、Open WebUI(API 模式) | 2GB | RackNerd 2GB | $18.29/年 |
| 中等 | Dify、FastGPT | 4GB | CloudCone 4GB | $42/年 |
| 重度 | Ollama 本地推理、MaxKB | 8GB+ | CloudCone 8GB | $78/年 |
关键前提:本文讨论的 AI 部署,绝大多数是 API 调用模式——VPS 上跑平台,AI 推理交给云端 API(DeepSeek、OpenAI 等)。这种模式不需要 GPU,普通 VPS 就能跑。真要在 VPS 上跑本地大模型,那是重度级别的事,文章最后会单独讲。
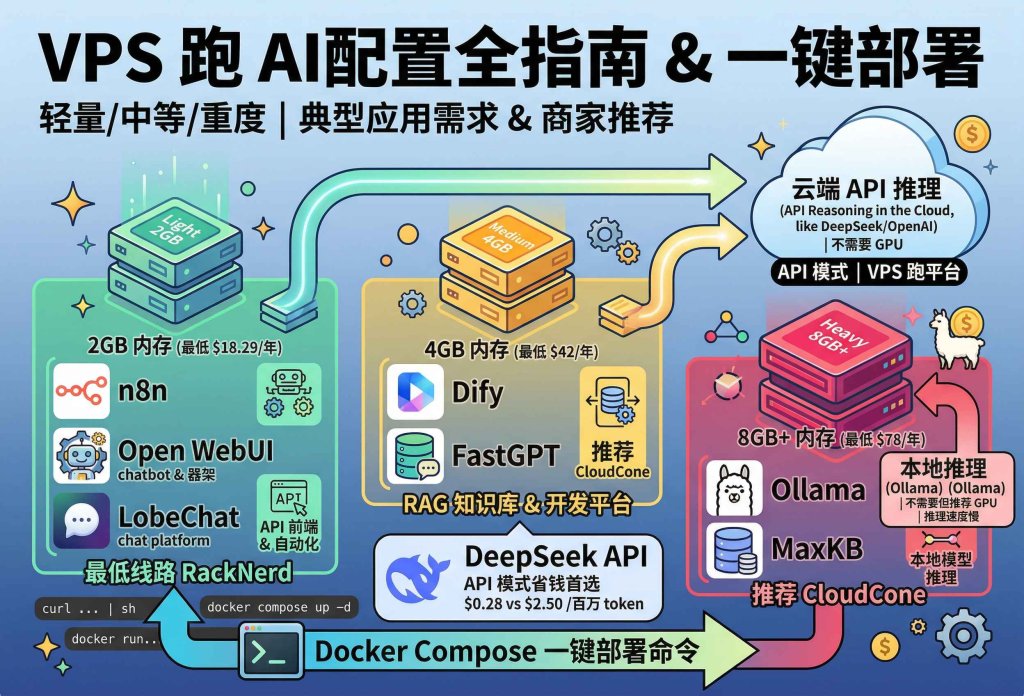
一、AI 应用配置需求一览
先把主流 AI 应用的最低配置需求摊开看:
| 应用 | 最低内存 | 最低 CPU | 最低硬盘 | 需要 GPU? | 用途 |
|---|---|---|---|---|---|
| n8n | 2GB | 2 核 | 20GB | 不需要 | AI 自动化工作流 |
| Open WebUI | 1GB(API 模式) | 1 核 | 10GB | 不需要 | AI 聊天前端 |
| LobeChat | 2GB | 1 核 | 10GB | 不需要 | AI 聊天平台 |
| Dify | 4GB | 2 核 | 20GB | 不需要 | LLM 应用开发平台 |
| FastGPT | 4GB | 2 核 | 50GB | 不需要 | RAG 知识库问答 |
| Ollama(小模型) | 8GB 系统 | 2 核 | 10GB+ | 不需要但推荐 | 本地模型推理 |
| MaxKB | 8GB | 4 核 | 100GB | 不需要 | 知识库问答系统 |
几个关键结论:
- 所有应用都支持 Docker Compose 部署,不用手动装依赖
- API 模式不需要 GPU——AI 推理在云端完成,VPS 只跑前端/工作流
- 内存是最关键的瓶颈,CPU 和硬盘反而不太紧张
- 想跑本地模型(Ollama),至少 8GB 内存起步,且只能跑 0.5B-3B 的小模型
二、轻量级:API 代理和自动化工作流(2GB 内存)
适合人群:用 DeepSeek/OpenAI API 搭建自动化工作流、AI 聊天界面、API 转发代理。
能跑什么?
n8n — AI 自动化工作流引擎。类似 Zapier 但开源免费、可自托管。能对接 DeepSeek API 实现:自动邮件处理、RSS 摘要生成、Telegram Bot、数据抓取分析等。2GB 内存够跑中等复杂度的工作流。
Open WebUI(API 模式) — AI 聊天前端。连接 OpenAI/DeepSeek API 就能用,界面漂亮、支持多模型切换。API 模式下 Open WebUI 本身只需 1GB 内存。
LobeChat — 另一个 AI 聊天平台。支持 OpenAI/Claude/DeepSeek 等多家 API。客户端模式只要 1-2GB 内存,带数据库的服务端模式建议 4GB+。
API 转发代理 — 如果你只是做 OpenAI/DeepSeek API 的中转代理(比如 one-api、new-api),1GB 内存就够。
推荐 VPS
| 商家 | 套餐 | 配置 | 年付价格 | 线路 | 购买 |
|---|---|---|---|---|---|
| RackNerd | 2GB 推荐 | 1 核 2GB 40GB SSD | $18.29/年 | 普通 | 购买 |
| CloudCone | 2GB | 3 核 2GB 30GB SSD | $23.50/年 | 普通 | 购买 |
| DMIT | Pro TINY | 1 核 2GB 20GB NVMe | $88.88/年 | CN2 GIA | 购买 |
| 搬瓦工 | KVM 2GB | 3 核 2GB 40GB SSD | $99.99/年 | 普通 | 购买 |
站长推荐:RackNerd 2GB $18.29/年。跑 n8n + DeepSeek API 绑绑有余,一年不到 130 块人民币。对线路有要求(晚高峰不卡)的选 DMIT Pro TINY $88.88/年。
三、中等级:RAG 知识库和 AI 开发平台(4GB 内存)
适合人群:搭建 AI 知识库、开发 AI 应用、同时跑多个 AI 服务。
能跑什么?
Dify — LLM 应用开发平台。可以搭建 AI 聊天机器人、RAG 知识库、AI Agent、工作流编排。官方要求最低 2 核 4GB 内存。Docker Compose 一键部署,包含 PostgreSQL + Redis + Weaviate 等组件。
FastGPT — 专注 RAG(检索增强生成)的知识库问答平台。可以上传文档、网页,AI 基于你的私有数据回答问题。最低 2 核 4GB,硬盘建议 50GB+(向量数据库吃空间)。
n8n + Dify 组合 — n8n 做工作流调度,Dify 做 AI 能力层,两者配合是目前最流行的企业级 AI 自动化方案。4GB 内存可以同时跑两者,但会比较紧张。
推荐 VPS
| 商家 | 套餐 | 配置 | 年付价格 | 线路 | 购买 |
|---|---|---|---|---|---|
| CloudCone | 4GB 推荐 | 6 核 4GB 60GB SSD | $42/年 | 普通 | 购买 |
| RackNerd | 4GB | 3 核 4GB 105GB SSD | $43.88/年 | 普通 | 购买 |
| HostDare | CSSD3 | 3 核 4GB 100GB NVMe | $180.74/年 | CN2 GIA | 购买 |
| Vultr | 高性能 | 2 核 4GB 128GB NVMe | $24/月 | 普通 | 购买 |
站长推荐:CloudCone 4GB 6 核 $42/年。6 个 CPU 核心跑 Docker 多容器很舒服,硬盘 60GB 也够 FastGPT 的向量数据库。RackNerd 4GB $43.88/年价格接近但硬盘更大(105GB),需要存大量文档数据的选这个。
需要 CN2 GIA 线路的话,HostDare CSSD3(4GB)原价 $180.74/年,用优惠码 DEAL50(7.5 折)约 $135/年,CN2 GIA 4GB 里算便宜的了。
四、重度级:本地模型推理(8GB+ 内存)
适合人群:想在 VPS 上跑本地 AI 模型(不调 API)、搭建私有化 AI 系统。
先说结论
在普通 VPS(无 GPU)上跑本地模型是可行但体验一般。VPS 的 CPU 跑 AI 推理速度很慢——一个 3B 参数的量化模型,CPU 推理速度大约 5-10 tokens/秒,对话时明显有延迟。能用,但别指望像 ChatGPT 那样秒回。
如果你能接受这个速度,或者场景是批量处理(不需要实时对话),VPS 跑本地模型是最省钱的方案。
能跑什么?
Ollama + Open WebUI — Ollama 是本地模型推理引擎,Open WebUI 是前端界面。组合起来就是一个私有 ChatGPT。VPS 上能跑的模型大小取决于内存:
| 内存 | 能跑的模型 | 代表模型 | 推理速度(CPU) |
|---|---|---|---|
| 8GB | 0.5B-1B 量化版 | Qwen2.5:0.5b、TinyLlama | 10-20 tok/s |
| 16GB | 3B-7B 量化版 | Phi-3 Mini、Qwen2.5:3b | 5-10 tok/s |
| 32GB | 7B-13B 量化版 | Llama 3.1:8b Q4 | 2-5 tok/s |
MaxKB — 知识库问答系统。官方要求 4 核 8GB 100GB 硬盘。MaxKB 自带向量数据库组件,所以配置要求比 FastGPT 高。
推荐 VPS
| 商家 | 套餐 | 配置 | 年付价格 | 线路 | 购买 |
|---|---|---|---|---|---|
| CloudCone | 8GB 推荐 | 10 核 8GB 120GB SSD | $78/年 | 普通 | 购买 |
| RackNerd | 6GB | 4 核 6GB 140GB SSD | $59.99/年 | 普通 | 购买 |
| Vultr | 高性能 8GB | 4 核 8GB 256GB NVMe | $48/月 | 普通 | 购买 |
站长推荐:CloudCone 8GB 10 核 $78/年。10 个 CPU 核心对本地模型推理有帮助(Ollama 默认用所有核心),120GB 硬盘够存几个模型。RackNerd 6GB $59.99/年也行,但内存少 2GB 且只有 4 核,跑 3B 模型会更吃力。
注意:如果你的目标是跑 7B 以上模型或需要实时对话体验,建议上 GPU 云服务器(Vultr GPU 实例、RunPod、Vast.ai 等),或者干脆用 API 模式——DeepSeek API 的性能和价格远优于在 VPS CPU 上跑本地模型。
| 级别 | 首选(最便宜) | 备选(CN2 GIA) | 年付预算 |
|---|---|---|---|
| 轻量(2GB) | RackNerd 2GB $18.29/年 | DMIT Pro TINY $88.88/年 | ¥130-640 |
| 中等(4GB) | CloudCone 4GB $42/年 | HostDare CSSD3 ~$117/年(用码 BF2025) | ¥300-850 |
| 重度(8GB) | CloudCone 8GB $78/年 | Vultr 8GB $48/月 | ¥560+ |
完整的商家详情和更多套餐选择参考。
六、DeepSeek API:最便宜的 AI 后端
在 VPS 上跑 AI 应用,核心问题不是 VPS 贵不贵,而是 AI API 花多少钱。目前最便宜的选择是 DeepSeek API。
DeepSeek V3.2 统一定价(2026 年 3 月)
| 模型 | 输入(缓存未命中) | 输入(缓存命中) | 输出 |
|---|---|---|---|
deepseek-chat(标准模式) |
$0.28 / 百万 token | $0.028 / 百万 token | $0.42 / 百万 token |
deepseek-reasoner(思考模式) |
$0.28 / 百万 token | $0.028 / 百万 token | $0.42 / 百万 token |
2026 年起 deepseek-chat 和 deepseek-reasoner 底层统一为 DeepSeek-V3.2,价格完全一致。
和其他 API 对比
| API 提供商 | 模型 | 输入价格 / 百万 token | 输出价格 / 百万 token |
|---|---|---|---|
| DeepSeek | V3.2 | $0.28 | $0.42 |
| OpenAI | GPT-4o | $2.50 | $10.00 |
| Anthropic | Claude Sonnet | $3.00 | $15.00 |
| Gemini Flash | $0.50 | $3.00 |
DeepSeek 输入价格是 GPT-4o 的 1/9,输出价格是 1/24。缓存命中时更夸张——输入只要 $0.028/百万 token,是 GPT-4o 的 1/89。
一个月要花多少钱?
按中等使用量估算(每天 50 次对话,每次约 2000 token 输入 + 1000 token 输出):
- DeepSeek:50 × 30 × (2000 × $0.28 + 1000 × $0.42) / 1,000,000 = $1.47/月
- GPT-4o:50 × 30 × (2000 × $2.50 + 1000 × $10.00) / 1,000,000 = $22.50/月
用 DeepSeek 的话,API 费用可以忽略不计。VPS $18.29/年 + API $1.47/月 × 12 = 总计 $35.93/年,约 260 元人民币。这比任何付费 AI 订阅都便宜。
七、一键部署命令
以下是各 AI 应用的 Docker Compose 一键部署命令。默认前提:VPS 已装好 Docker 和 Docker Compose。
安装 Docker(如果还没装)
curl -fsSL https://get.docker.com | sh
1. n8n(轻量级,推荐 2GB+)
mkdir -p ~/n8n && cd ~/n8n
cat > docker-compose.yml << 'EOF'
services:
n8n:
image: docker.n8n.io/n8nio/n8n
restart: always
ports:
- "5678:5678"
environment:
- N8N_HOST=0.0.0.0
- N8N_PROTOCOL=http
- GENERIC_TIMEZONE=Asia/Shanghai
volumes:
- n8n_data:/home/node/.n8n
volumes:
n8n_data:
EOF
docker compose up -d
部署完成后访问 http://你的IP:5678,在 n8n 里添加 HTTP Request 节点调用 DeepSeek API 即可。
2. Open WebUI + DeepSeek API(轻量级,推荐 2GB+)
docker run -d -p 3000:8080 \
-e OPENAI_API_BASE_URL=https://api.deepseek.com/v1 \
-e OPENAI_API_KEY=你的DeepSeek_API_Key \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
访问 http://你的IP:3000,开箱即用的 AI 聊天界面。
3. LobeChat(轻量级,推荐 2GB+)
docker run -d -p 3210:3210 \
-e OPENAI_API_KEY=你的DeepSeek_API_Key \
-e OPENAI_PROXY_URL=https://api.deepseek.com/v1 \
--name lobe-chat \
--restart always \
lobehub/lobe-chat
访问 http://你的IP:3210。
4. Dify(中等级,推荐 4GB+)
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
docker compose up -d
访问 http://你的IP。首次启动需要几分钟拉取镜像。在 Dify 后台添加 DeepSeek 作为模型供应商即可。
5. Ollama + Open WebUI(重度级,推荐 8GB+)
# 安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 拉一个小模型测试
ollama pull qwen2.5:0.5b
# 启动 Open WebUI 连接本地 Ollama
docker run -d -p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
访问 http://你的IP:3000,选择 qwen2.5:0.5b 模型开始对话。
八、常见问题
1、没有 GPU 能跑 AI 吗?
能,分两种情况:
- API 模式(推荐):VPS 只跑前端/工作流平台,AI 推理交给 DeepSeek/OpenAI 等云端 API。完全不需要 GPU,2GB 内存的 VPS 就够。
- 本地模型:用 Ollama 跑量化版小模型(0.5B-3B),CPU 推理可以用但速度慢(5-20 tok/s)。8GB 内存起步。
除非你有特殊的数据隐私需求(不能让数据出服务器),否则 API 模式性价比远高于本地推理。
2、DeepSeek API 稳定吗?
2026 年以来稳定性不错,偶尔有高峰期限流。建议在 n8n/Dify 里同时配置 DeepSeek 和 OpenAI 两个 API,做故障自动切换。
3、VPS 线路对 AI 应用有影响吗?
有。如果你在国内访问 VPS 上的 AI 应用(比如打开 Open WebUI 聊天),CN2 GIA 线路的体验明显好于普通线路——延迟低、不卡顿。
但如果 VPS 到 AI API(比如 VPS 调用 DeepSeek API),线路影响不大,因为 VPS 和 API 都在海外,走国际线路即可。
简单说:人→VPS 走 CN2 GIA 有意义,VPS→API 走普通线路就行。
4、2GB 内存够跑 Dify 吗?
不够。Dify 官方要求最低 4GB。2GB 可以强制启动,但 PostgreSQL + Redis + Weaviate 几个组件加起来内存占满后会频繁 OOM。别省这个钱。
5、Ollama 跑 7B 模型需要多大内存?
Q4 量化版的 7B 模型(如 Llama 3.1:8b),模型本身约占 4-5GB 内存,加上系统和 Ollama 进程开销,至少需要 16GB 系统内存。8GB 的 VPS 只能跑 3B 以下模型。
6、有没有一台 VPS 同时跑多个 AI 服务?
可以,但要算好内存:
- n8n(~500MB)+ Open WebUI(~300MB)→ 2GB VPS 可以同时跑
- n8n + Dify → 至少 6GB
- Dify + Ollama(0.5b 模型)→ 至少 8GB
站长建议:轻量应用放一台便宜 VPS,中重度应用单独开一台。
九、总结
| 你想干什么 | 推荐方案 | 最低预算 |
|---|---|---|
| AI 聊天界面(Open WebUI/LobeChat) | 2GB VPS + DeepSeek API | $18.29/年 + API ~$1/月 |
| AI 自动化工作流(n8n) | 2GB VPS + DeepSeek API | $18.29/年 + API ~$1/月 |
| AI 知识库/RAG(Dify/FastGPT) | 4GB VPS + DeepSeek API | $42/年 + API ~$2/月 |
| 本地模型推理(Ollama) | 8GB VPS,无需 API | $78/年 |
| 私有 ChatGPT(全套) | 8GB VPS + DeepSeek API | $78/年 + API ~$3/月 |
站长最推荐的组合:RackNerd 2GB($18.29/年)+ DeepSeek API。一年总花费不到 300 元人民币,就能拥有一个 7×24 小时在线的私有 AI 助手 + 自动化工作流。
想要更好体验(CN2 GIA 线路):DMIT Pro TINY($88.88/年)+ DeepSeek API,总花费约 660 元/年,延迟低、速度快。
预算充足跑知识库:CloudCone 4GB($42/年)+ Dify + DeepSeek API,企业级 AI 知识库方案,年总花费 350 元左右。
更多 VPS 选择参考,CN2 GIA 线路方案参考。





